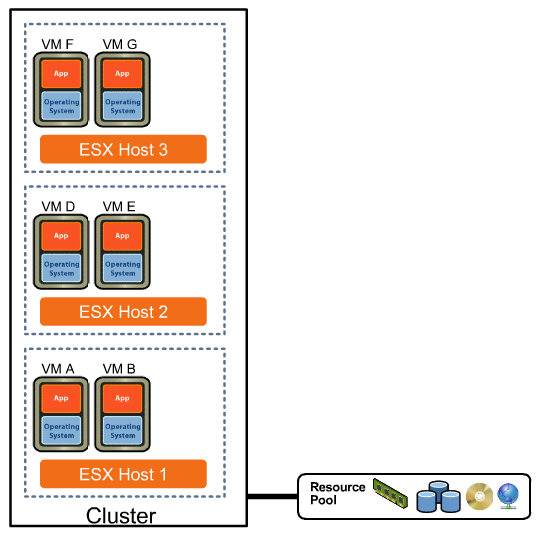
VMware HA (High Availability) is a major step in setting up a disaster recovery objective. With HA enabled, each ESXi host checks in on the other hosts and looks for a failure, if a failure should occur the VMs on the failed host are restarted on another server. To enable HA on your network a few prerequisites are required; All VMs and their configuration files must reside on a shared storage, this is required so that all the hosts have access to the VM if the host running it should fail; Each host in a VMware HA cluster must have a host name and a static IP, this will guarantee that each host can monitor each other without having false positives on failure if a host changes IP address; Hosts must be configured to have access to the VM network; Finally VMware recommends a redundant network connection, if a network card should fail this would allow communication to the host it is associated with, without this redundancy the host would seen as failing.
Host Monitoring
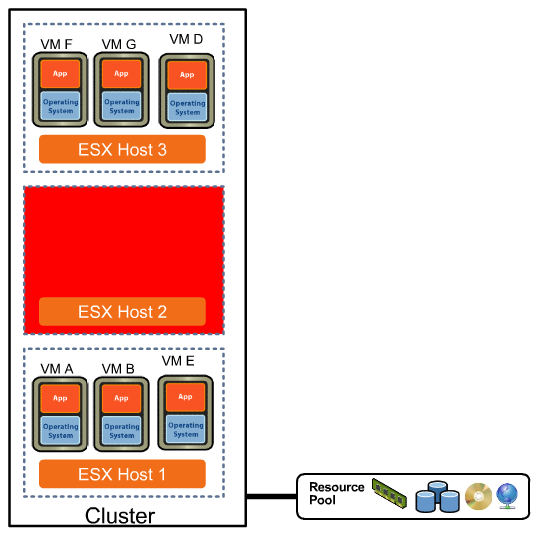
VMware HA host monitoring is installed on up to 5 ESX hosts to monitor the heartbeat among all the servers. One of the hosts is the primary active host, which is the main host that reacts to the situation. All 5 hosts are given the tools and if the primary active host was to shut off, one of the four other hosts would take over its roll. Each host checks for a hearbeat every second, if the host cannot find a heartbeat from one of its hosts within 15 seconds, it is considered down and the Virtual Machines are restarted on a different host.
Admission Control
Admission Control sets the rules on which VMs can be powered on. If the network is running near capacity and a host fails, these settings would restrict which VMs can be restarted if only limited CPU or memory resources are available, this is done by giving priority to different VMs, with mission critical VMs given the highest priority. Finally you can allow VMs to be powered on even if they violate the constraints but failover is not guaranteed.
Enabling HA and DRS
DRS (Distributed Resource Management) is its own feature in itself and moves VMs around with vMotion based upon the current work loads of each host, as a host reaches capacity it will use vMotion to move the VM to another host. If a host should fail each VM is assigned a host to be restarted on, but this is decided upon ahead of time and as each VM is restarted there might be other hosts using less resources that would be better suited. Having DRS enabled with HA allows these restarted VMs to be moved with vMotion to the better suited host.
While HA is not as feature rich as VMware Fault Tolerance, it is a major step to ensuring that server downtime is kept to a minimum and that the network is proactively monitoring itself.





