With a VMware vSphere Health Check, one of our VMware Certified Professional consultants (VCPs) will work with your IT team and assist them with configuration and management of VMware vSphere by providing knowledge and guidance on best practices. If you're running the latest in VMware software, it is important that you are getting the most out of your environment. By working closely with your IT department our VCP will be able to provide concrete recommendations that will optimize your virtual IT infrastructure.
WHY THIS MATTERS: Over time, adding new VM's and changes/upgrades to your virtual environment alters the efficiency. Having a VMware Health Check ensures you’re not over/under utilizing resources and your environment is staying within VMware’s best practices guidelines. Its a good idea to have a VCP check your environment every 6 to 12 months or a couple months after any major upgrade or change to the infrastructure. This ensures your infrastructure is well maintained and that any problems are realized before they require a major overhaul.
Benefits
• Optimize VMware vSphere performance
• Maximize resources through efficiencies and roadmap for future improvements
• Mitigate risk by leveraging experienced consultants and proven best practices
Deliverables
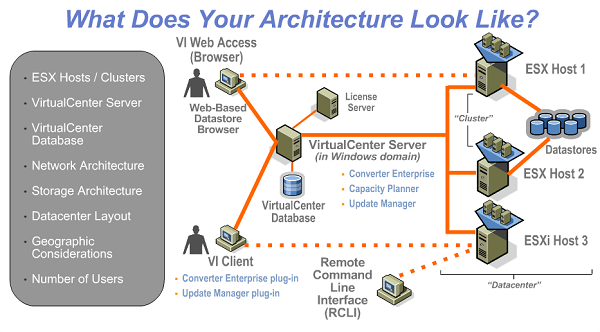
• Collect data and conduct assessment of VMware vSphere (up to four ESX™ hosts)
• Identify potential opportunities to optimize configuration and improve performance
• Hold an interactive workshop to facilitate knowledge transfer on VMware vSphere best practice
Scope
• Up to two (2) days on-site, and one (1) day off-site to create assessment report
• Health Check includes up to four (4) ESX hosts
• Maximum of five (5) participants for interactive workshop
• Contact your local VMware representative for pricing information
• VMware vSphere Health Check will be delivered by a VMware Certified Professional (VCP) consultant
Requirements
• Existing VMware vSphere including VMware ESX
• Administrator (root) access to VMware installations
• Conference room with projector and networked desktops/laptops running MS Windows® 2000 or higher
You've made an investment in your virtual infrastructure, so ensuring that you are getting the most out of this investment is key. By having a VCP consultant optimize your environment you not only ensure that vSphere is running to the best of its abilities, but also gives your IT the knowledge and training to maintain the virtual infrastructure.
Go Here to get the WhitePaper Outlining the Health Check processs and VMware best practices that are reviewed